
Are University Towns Housing Prices Less Affected by Recession?
An important part of the data science process is asking a question, gathering and analyzing the data needed to answer that question and test our hypothesis on the topic against that data.
One such question is, Are university towns housing prices less affected by recession? In this data analysis project, we will formulate a hypothesis around this question, gather and process required data and finally test our hypothesis.
Strategy
We will use 3 data sources for this project.
We will use GDP data from Bureau of Economic Analysis, US Department of Commerce, the GDP over time of the United States in current dollars (using the chained value in 2009 dollars), in quarterly intervals, in the file gdplev.xls. We will use this data to determine recession periods. For this project, we will only look at GDP data from the first quarter of 2000 onward.
We will use housing price data from the Zillow research data site. There is housing data for the United States. In particular the data file for all homes at a city level, City_Zhvi_AllHomes.csv, has median home sale prices at a fine grained level.
We will use a list of university towns collected from Wikipedia to divide the housing price data in two sets as university towns and non-university towns. We have this data in the university_towns.txt file.
So, we will use the above mentioned data sources and manipulate and transform them to test our hypothesis.
All the data and the notebook can be found in my github profile
Hypothesis
University towns have their mean housing prices less affected by recessions.
Required Definitions
- A quarter is a specific three month period, Q1 is January through March, Q2 is April through June, Q3 is July through September, Q4 is October through December.
- A recession is defined as starting with two consecutive quarters of GDP decline, and ending with two consecutive quarters of GDP growth.
- A recession bottom is the quarter within a recession which had the lowest GDP.
- A university town is a city which has a high percentage of university students compared to the total population of the city.
First, let's import necessary libraries.
import pandas as pd
import numpy as np
from scipy.stats import ttest_ind
from matplotlib import pyplot as plt
%matplotlib inline
We need to make a list of university towns out of the text file. Let's sort that out.
def get_list_of_university_towns():
'''Returns a DataFrame of towns and the states they are in from the
university_towns.txt list. The format of the DataFrame should be:
DataFrame( [ ["Michigan", "Ann Arbor"], ["Michigan", "Yipsilanti"] ],
columns=["State", "RegionName"] )
The following cleaning needs to be done:
1. For "State", removing characters from "[" to the end.
2. For "RegionName", when applicable, removing every character from " (" to the end.
3. Remove newline character '\n'. '''
ut_list = []
with open('university_towns.txt') as f:
for line in f:
if 'edit' in line:
current_city = line.split('[')[0].strip()
else:
ut_list.append((current_city, line.split('(')[0].strip()))
ut_df = pd.DataFrame.from_records(ut_list)
ut_df.columns = ['State', 'RegionName']
return ut_df
Let's take a look at the output of this function.
ut_df = get_list_of_university_towns()
ut_df.head()
| Serial | State | RegionName |
|---|---|---|
| 0 | Alabama | Auburn |
| 1 | Alabama | Florence |
| 2 | Alabama | Jacksonville |
| 3 | Alabama | Livingston |
| 4 | Alabama | Montevallo |
So far so good.
Now, let's get the gdp data sorted out. We will only use data from 2000 onwards.
def get_gdp_df():
'''this function reads the gdp data and returns a dataframe with only the required columns'''
gdplev = pd.ExcelFile('gdplev.xls')
gdplev = gdplev.parse("Sheet1", skiprows=219)
gdplev = gdplev[['1999q4', 9926.1]]
gdplev.columns = ['quarter','gdp']
return gdplev
Here, we are reading the excel file into a dataframe, skipping some initial rows to only include data from 2000 onwards and only keeping two columns, one that includes the quarter information and the other contains the gdp in chained billion dollars.
Let's look at the gdp data visually first.
gdp = get_gdp_df()
ax = gdp.plot.bar(title='gdp in quarters', figsize=(20, 10), legend=True, x='quarter', y='gdp')
plt.show()
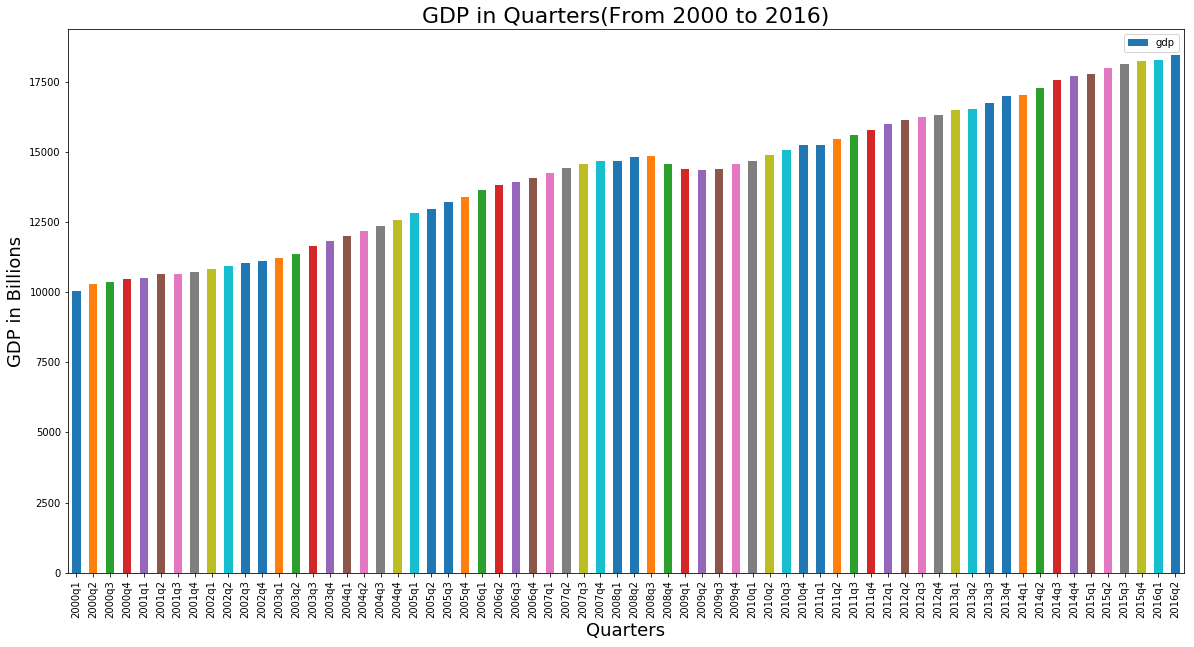
We can see there's small dip in the middle. Let's find out the recession period and look at it more closely.
def get_recession_start():
'''Returns the year and quarter of the recession start time as a
string value in a format such as 2005q3'''
gdplev = get_gdp_df()
for i in range(2, len(gdplev)):
if (gdplev.iloc[i-2][1] > gdplev.iloc[i-1][1]) and (gdplev.iloc[i-1][1] > gdplev.iloc[i][1]):
return gdplev.iloc[i-2][0]
The above function finds the start of a recession based on the definition above. Let's run this and find the starting point for recession.
get_recession_start()
'2008q3'
So, within our window of analysis, a recession had started in the 3rd quarter of 2008 as is well known
This function finds the end of a recession according to the definition.
def get_recession_end():
'''Returns the year and quarter of the recession end time as a
string value in a format such as 2005q3'''
gdplev = get_gdp_df()
start = get_recession_start()
start_index = gdplev[gdplev['quarter'] == start].index.tolist()[0]
gdplev=gdplev.iloc[start_index:]
for i in range(2, len(gdplev)):
if (gdplev.iloc[i-2][1] < gdplev.iloc[i-1][1]) and (gdplev.iloc[i-1][1] < gdplev.iloc[i][1]):
return gdplev.iloc[i][0]
Let's run this and find out the end of the recession period
get_recession_end()
'2009q4'
So, the recession ended in the last quarter of 2009. It lasted over a year!
Now let's figure out the bottom of the recession
def get_recession_bottom():
'''Returns the year and quarter of the recession bottom time as a
string value in a format such as 2005q3'''
gdp = get_gdp_df()
a = gdp.index[gdp['quarter'] == get_recession_start()][0]
b = gdp.index[gdp['quarter'] == get_recession_end()][0]
return gdp.iloc[gdp.iloc[a:b+1, 1 ].idxmin(), 0]
get_recession_bottom()
'2009q2'
Now, that we have figured out the recession period, let's visualize the period.
recession_start_index = gdp.loc[gdp.quarter == get_recession_start(), :].index[0]
recession_end_index = gdp.loc[gdp.quarter == get_recession_end(), :].index[0]
# we take two previous quarters before recession into account to capture the start of recession in the graph
recession = gdp.iloc[recession_start_index-2: recession_end_index+1, :]
recession.set_index('quarter').plot.line(title='gdp in quarters', figsize=(20, 10), style='-', marker='o')
plt.xticks([x for x in range(len(recession.index))], recession.quarter)
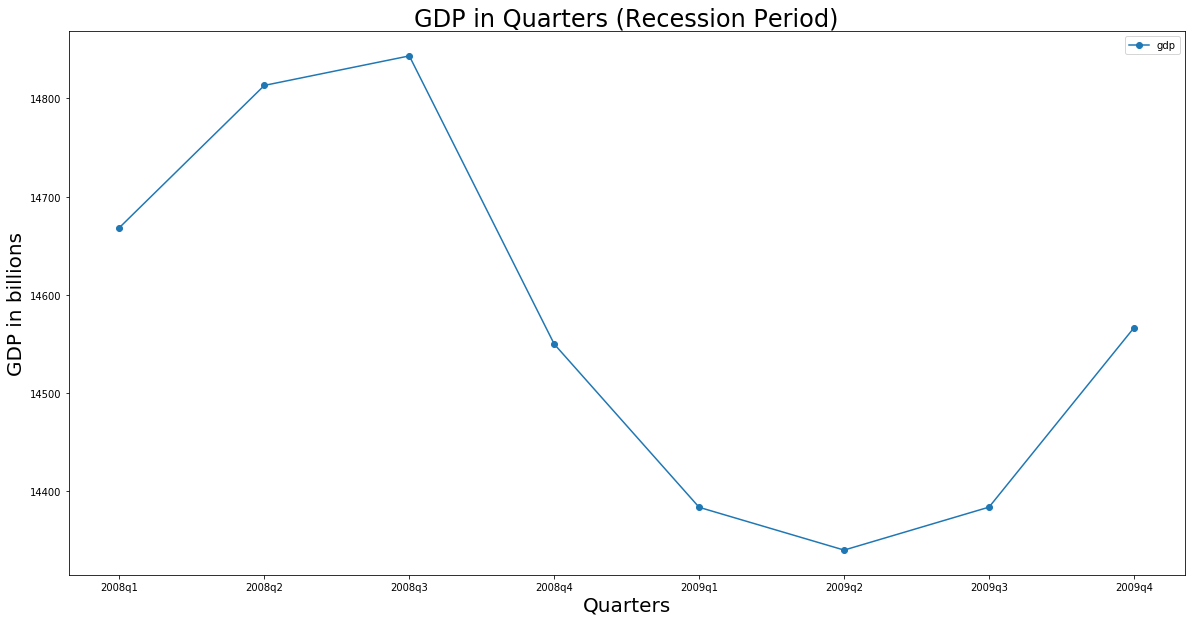
So, the 2nd quarter of 2009 had the lowest GDP. We can see two consecutive decrease starting from 2008q3 and two consecutive growth starting from 2009q3. So, 2009q4 marks the end of this recession period.
So, we have determined the important data points related to recession. Let's look into the housing price data now.
zillow = pd.read_csv('City_Zhvi_AllHomes.csv')
zillow.shape
(10730, 251)
So, after the first look at the data it seems we need the following cleaning:
- The states are in short names, so we need to transform this.
- It contains month by month prices from 1996, we only need data from 2001 so drop the unnecessary columns.
- Use the state and region name for indexing.
- Finally, convert month by month data to quarterly data.
So, let's get to work!
def convert_housing_data_to_quarters():
'''Converts the housing data to quarters and returns it as mean housing price
values in a dataframe. This is a dataframe with
columns for 2000q1 through 2016q3, and have a multi-index
in the shape of ["State","RegionName"].
Note: Quarters are defined in the definition, they are
not arbitrary three month periods.
'''
zillow = pd.read_csv('City_Zhvi_AllHomes.csv')
zillow['State'] = zillow['State'].map(states)
zillow.set_index(['State', 'RegionName'], inplace=True)
zillow = zillow.loc[:, '2000-01': ]
new_columns = [str(x)+y for x in range(2000, 2017) for y in ['q1', 'q2', 'q3', 'q4']]
new_columns = new_columns[:-1] # drop the last quarter of 2016
x = 0
for c in new_columns:
zillow[c] = zillow.iloc[:, x:x+3].mean(axis=1)
x = x+3
zillow = zillow.loc[:, '2000q1':]
return zillow
Let's take a look at the shape of the transformed zillow data. It should have the same number of rows as the original file that is 10730 and the number of columns should be 67 (4 quarters in 17 years minus the last quarter in 2016)
convert_housing_data_to_quarters().shape
(10730, 67)
So, the data is prepared as desired. Now, we will move into the final phase of the analysis.
- We only need to look at the recession period, so we will narrow the columns to recession period.
- We need a price ratio column to compare the prices between the start and bottom of the recession.
- We need to split the data into university towns and non-university towns to run t-test on our hypothesis.
def run_ttest():
'''First creates new data showing the decline or growth of housing prices
between the recession start and the recession bottom. Then runs a ttest
comparing the university town values to the non-university towns values,
return whether the alternative hypothesis (that the two groups are the same)
is true or not as well as the p-value of the confidence.
Returns the tuple (different, p, lower) where different=True if the t-test is
True at a p<0.01 (we reject the null hypothesis), or different=False if
otherwise (we cannot reject the null hypothesis). The
value for lower should be either "university town" or "non-university town"
depending on which has a lower mean price ratio (which is equivilent to a
reduced market loss).'''
# get the start of recession
start = get_recession_start()
#get the bottom of the recession
bottom = get_recession_bottom()
# get the zillow housing data in desired format
housing_data = convert_housing_data_to_quarters()
# keep only the columns from recession starting point and bottom.
housing_data = housing_data.loc[:, start: bottom]
# compute price ratio between the recession points and add it as a column.
housing_data.reset_index(inplace=True)
housing_data['price_ratio'] = (housing_data[start] - housing_data[bottom]) / housing_data[start]
# get the university town list to split the data.
uni_towns = get_list_of_university_towns()
uni_town_list = uni_towns['RegionName'].tolist()
# add a column to use as splitting condition
housing_data['isUniTown'] = housing_data.RegionName.apply(lambda x: x in uni_town_list)
#split the data into two separate dataframes and drop rows with missing values. The dropping step is needed to
#perform the t-test
uni_data = housing_data[housing_data.isUniTown].copy().dropna()
not_uni_data = housing_data[~housing_data.isUniTown].copy().dropna()
# get the p-value by applying t-test on these two dataframe columns.
p = ttest_ind(uni_data['price_ratio'], not_uni_data['price_ratio'])[1]
# this boolean value will tell us whether we can reject the null hyopthesis or not.
different = p < 0.01
# this metric will tell us which type of town has the lower housing price ratio (mean) during the recession
lower = 'university town' if uni_data['price_ratio'].mean() < not_uni_data['price_ratio'].mean() else 'non-university town'
return (different, p, lower)
Now, let's run the ttest to validate our hypothesis!
run_ttest()
(True, 0.00036641601595526971, 'university town')
The p-value is well below the 0.05 threshold and so we can reject the null hypothesis and claim that housing prices in university towns are less affected by recession.
So, we have gone from collecting the data to cleaning and visualizing it and finally testing out hypothesis against it.